日处理20亿数据 实时用户行为服务系统架构实践
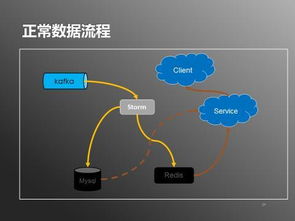
随着互联网业务的快速发展,用户行为数据已成为驱动产品优化、精准营销和智能决策的核心资产。面对每日高达20亿条数据的处理需求,构建一个高可用、低延迟、可扩展的实时用户行为服务系统至关重要。本文将深入探讨支撑如此庞大数据量的系统架构设计、关键组件选型及实践挑战。
一、 系统核心目标与挑战
在日处理20亿数据的规模下,系统设计需满足以下核心目标:
1. 高吞吐与低延迟:数据产生后需在秒级甚至毫秒级内完成采集、处理与可查询。
2. 高可用与容错:系统需保证7x24小时稳定运行,任何单点故障不应影响整体服务。
3. 水平可扩展:架构需能通过增加节点平滑应对数据量的持续增长。
4. 数据一致性:在分布式环境下,需在最终一致性与查询实时性之间取得平衡。
主要挑战包括海量数据的快速摄入、实时计算资源调度、存储成本控制以及复杂查询的响应效率。
二、 整体架构设计
一个典型的实时用户行为数据处理服务系统通常采用分层架构,自下而上分为数据采集层、消息缓冲层、实时计算层、存储服务层和应用接口层。
1. 数据采集层
轻量级SDK:在客户端(Web/App/小程序)嵌入轻量级SDK,负责收集页面浏览、点击、启动等事件,进行初步格式化与压缩。
网关集群:SDK将数据发送至高可用的网关集群(如Nginx + OpenResty),网关负责负载均衡、初步验签、限流及将数据异步推送至下游消息队列。此层需具备极强的横向扩展能力。
2. 消息缓冲层
* 分布式消息队列:选用高吞吐、支持持久化的消息中间件,如Apache Kafka或Pulsar。该层作为系统的“主动脉”,解耦采集与处理,应对流量峰值,并保证数据不丢失。针对20亿/天的数据量,需对Kafka集群进行合理的Topic分区规划与副本配置。
3. 实时计算层
流处理引擎:这是系统的“大脑”。采用Apache Flink作为核心流处理框架,其精确一次(Exactly-Once)语义、高吞吐和低延迟特性非常适合实时用户行为分析。
计算任务:Flink作业从Kafka消费数据,进行一系列处理:
* 数据清洗与格式化:过滤无效数据,统一字段格式。
- 实时统计:进行窗口聚合计算(如每分钟活跃用户数、事件计数)。
- 规则匹配与触发:对接预设规则(如用户完成特定路径后发券),实时输出触发事件。
- 多维关联:将行为事件与用户画像、物料信息等进行实时关联,丰富数据维度。
- 该层通常以YARN或Kubernetes作为资源调度平台,实现计算任务的弹性扩缩容。
4. 存储服务层
实时存储:处理后的实时结果(如聚合指标、触发事件)需要被快速写入和查询。可选用:
OLAP数据库:如ClickHouse或Doris,用于支持高速、多维的即时查询(Ad-hoc Query)。
- 宽表数据库:如HBase/Cassandra,以KV或宽表形式存储明细或用户粒度聚合数据,支持快速点查。
- 时序数据库:如InfluxDB,专门存储时间序列化的指标数据。
- 冷备份与离线分析:原始数据及历史明细可定期归档至HDFS或对象存储(如S3/OSS),供离线数据仓库(如Hive)进行深度挖掘与批量报表生成。
5. 应用接口层
对外提供统一的RESTful API或GraphQL接口,供业务系统(如运营平台、推荐系统、风控系统)查询实时用户行为指标、标签或接收实时事件推送。
通常需要聚合查询网关,根据查询条件路由至不同的底层存储引擎。
三、 关键实践与优化
- 数据分片与压缩:在Kafka、Flink State及存储系统中,合理设计分区键(如
user_id),使数据均匀分布。采用高效的压缩算法(如Snappy、LZ4)减少网络与存储IO。 - 资源动态调度:基于Kafka Lag监控和系统负载,自动伸缩Flink任务并行度及计算资源,在成本与性能间取得平衡。
- 多级缓存:在查询网关和API层引入Redis等缓存,存储热点查询结果,大幅降低对底层存储的压力,提升查询响应速度。
- 监控与告警体系:建立全方位的监控,涵盖从数据采集延迟、Flink Checkpoint时长、Kafka堆积量到各存储节点负载、API响应时间等关键指标,并设置智能告警。
- 数据治理与质量:定义清晰的数据规范,在流处理环节进行严格的数据质量校验(如非空、枚举值、关联存在性),并建立数据血缘追踪,确保数据的可信度。
四、
构建日处理20亿数据的实时用户行为服务系统是一项复杂的系统工程,其核心在于一个流式驱动的、各层解耦的、可水平扩展的架构。通过合理组合像Kafka、Flink、ClickHouse这样经过大规模实践验证的组件,并辅以精细化的资源管理、数据治理和监控运维,能够有效应对海量数据实时处理的挑战,将数据流转化为驱动业务增长的实时价值流。随着流批一体技术和云原生数据基础设施的成熟,此类系统的构建与运维将更加高效与智能。
如若转载,请注明出处:http://www.puyanghuayuwangluo.com/product/50.html
更新时间:2026-06-19 19:28:19